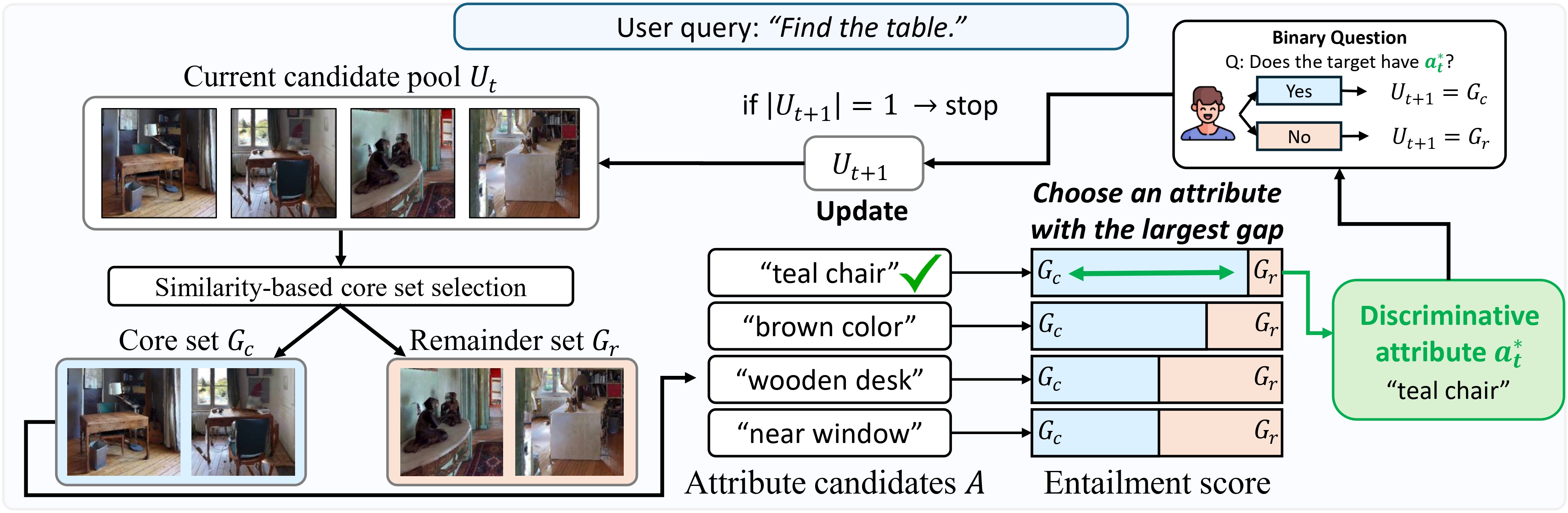
Three strategies for ambiguous instance navigation
Prior work on collaborative instance navigation typically follows independent matching, scoring each candidate against accumulated facts. A natural way to reduce premature decisions is to defer the choice until several candidates are collected (pooled independent matching). ProCompNav goes further with comparative judgment: at each round it picks an attribute-value pair that splits the current pool and asks a single yes/no question to prune it.
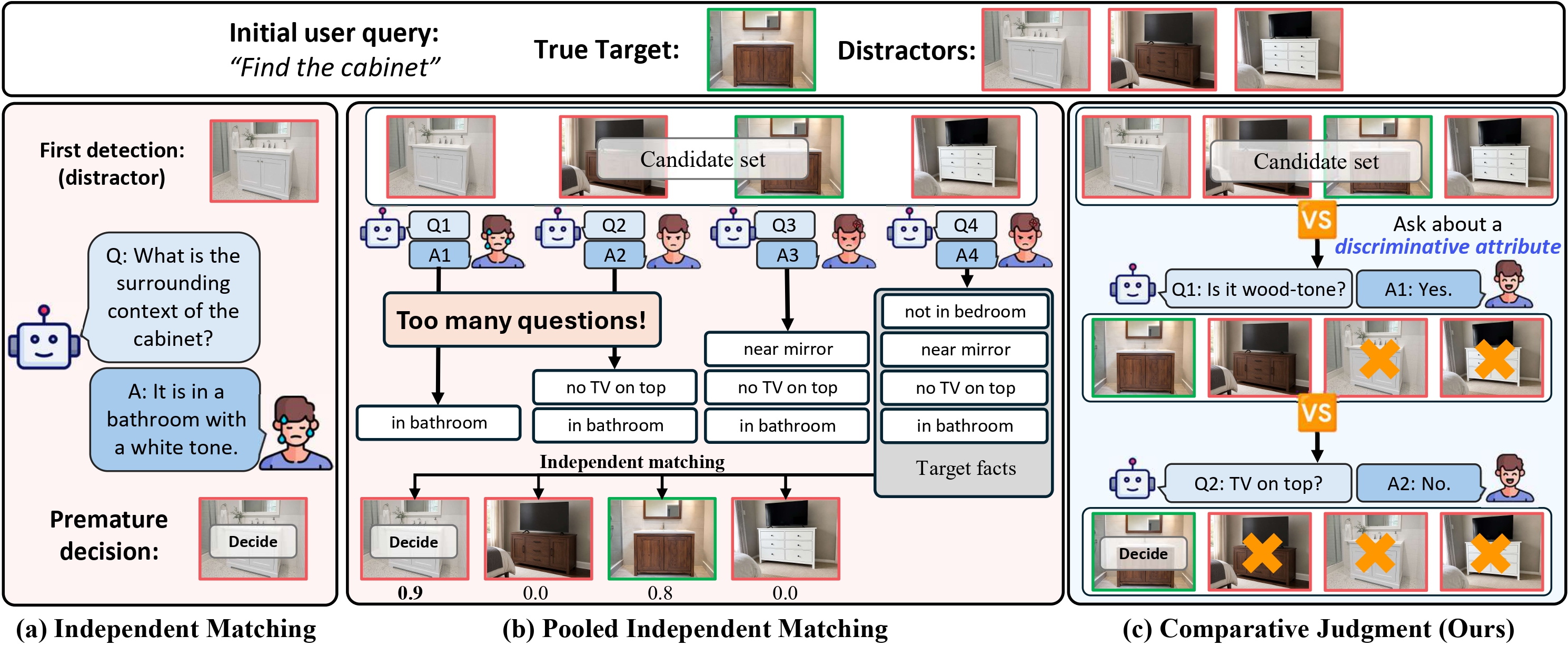
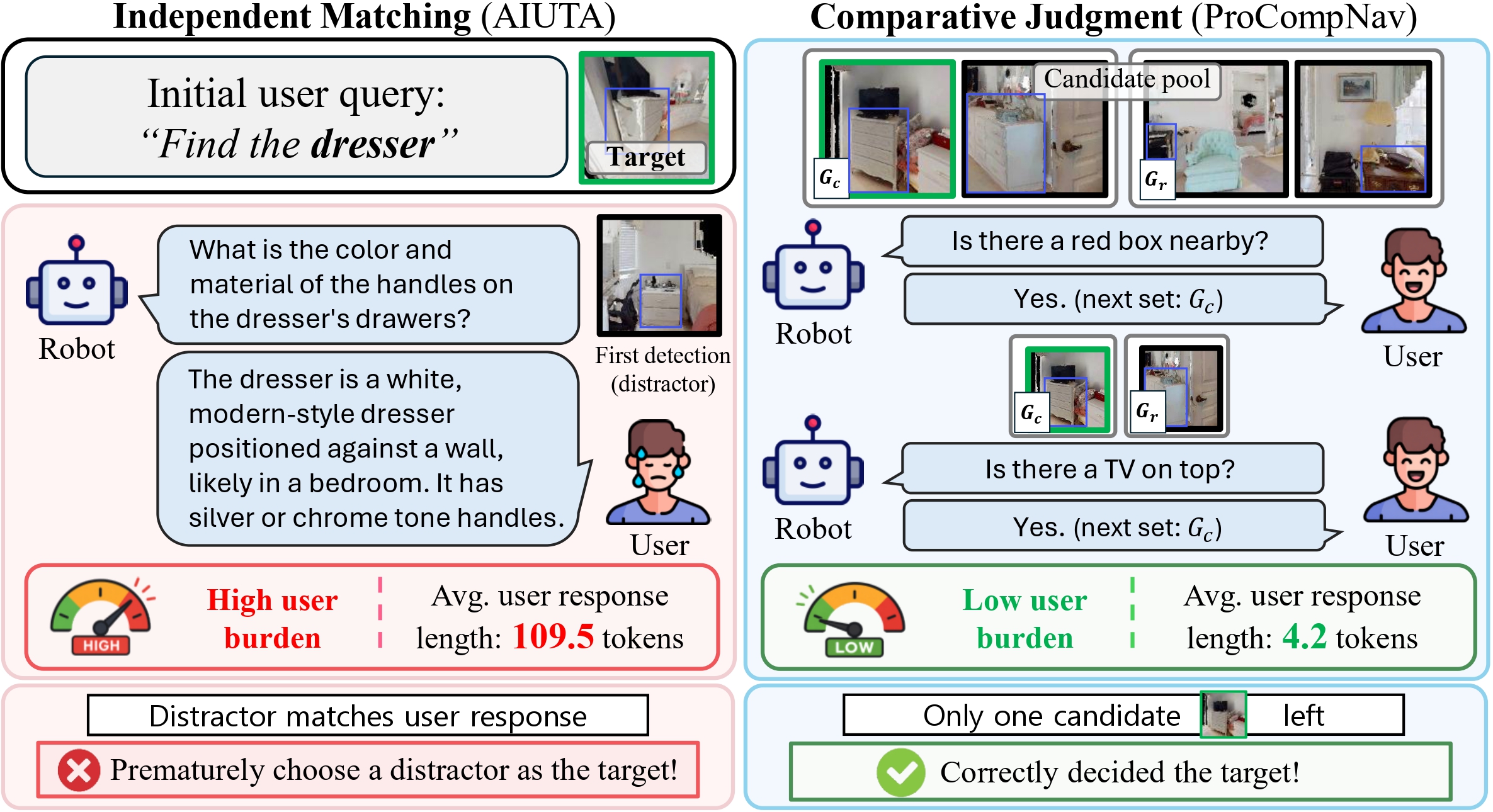
Figure 1. Three strategies for instance navigation under an ambiguous user query. (a) Independent Matching scores each candidate independently, causing premature decision to a distractor sharing attributes with the true target. (b) Pooled Independent Matching defers the decision until multiple candidates are collected, but non-discriminative questions still fail to separate similar distractors, while imposing high user burden. (c) Comparative Judgment (Ours) proactively builds a candidate pool and asks binary questions about discriminative attributes derived from candidate contrasts, accurately identifying the target with minimal user burden.
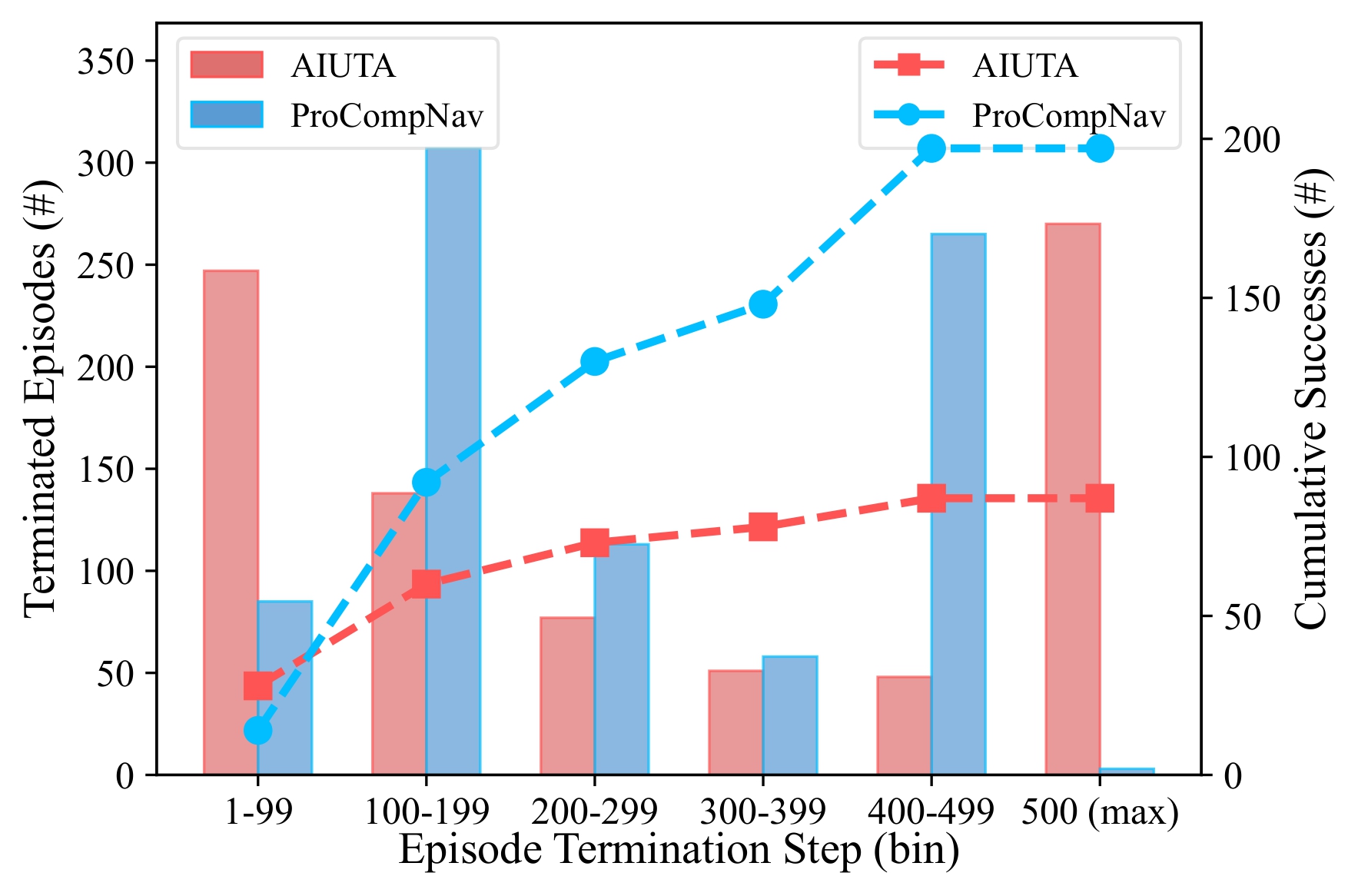
Table 1 isolates the contribution of each ingredient on CoIN-Bench. Adding a candidate pool to independent matching (b) lifts SR but inflates user response length 4×; replacing independent matching with comparative judgment (c) lifts SR further while collapsing Response Length from 460–520 to 4.2–4.3 tokens.
| Decision Strategy | Stage | Val Seen | Val Seen Synonyms | Val Unseen | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pool | Compare | SR↑ | RL↓ | NQ↓ | SR↑ | RL↓ | NQ↓ | SR↑ | RL↓ | NQ↓ | |
| (a) Independent Matching [Taioli et al., 2025] | ✗ | ✗ | 10.5 | 109.5 | 1.2 | 15.3 | 129.2 | 1.2 | 8.9 | 122.8 | 1.3 |
| (b) Pooled Independent Matching | ✓ | ✗ | 17.5 | 460.2 | 3.6 | 22.0 | 519.2 | 3.7 | 13.3 | 467.7 | 3.4 |
| (c) Comparative Judgment (Ours) | ✓ | ✓ | 23.7 | 4.2 | 2.2 | 28.1 | 4.3 | 2.2 | 17.0 | 4.2 | 2.3 |
Table 1. Comparison of three disambiguation strategies on CoIN-Bench. We report Success Rate (SR), average total Response Length (RL), and average Number of Questions (NQ) per episode.